Caractères#
Pour pouvoir écrire, afficher ou stocker un texte sur un ordinateur, il faut définir une représentation des caractères compréhensibles pour celui-ci. L'idée la plus simple est de faire correspondre à chaque caractère un numéro unique.
Il existe plusieurs codes utilisés. ASCII et UTF-8 sont les plus courants.
Code ASCII#
Dans les années 50, ils existaient beaucoup d'encodages différents pour les caractères, ce qui posait des problèmes de compatibilité et rendait les échanges compliqués. Au début des années 60, l'ANSI (American National Standards Institute) propose la norme de codage pour les caractères appelée ASCII (American Standard Code for Information Interchange). Cette norme définit 128 caractères sur 7 bits.
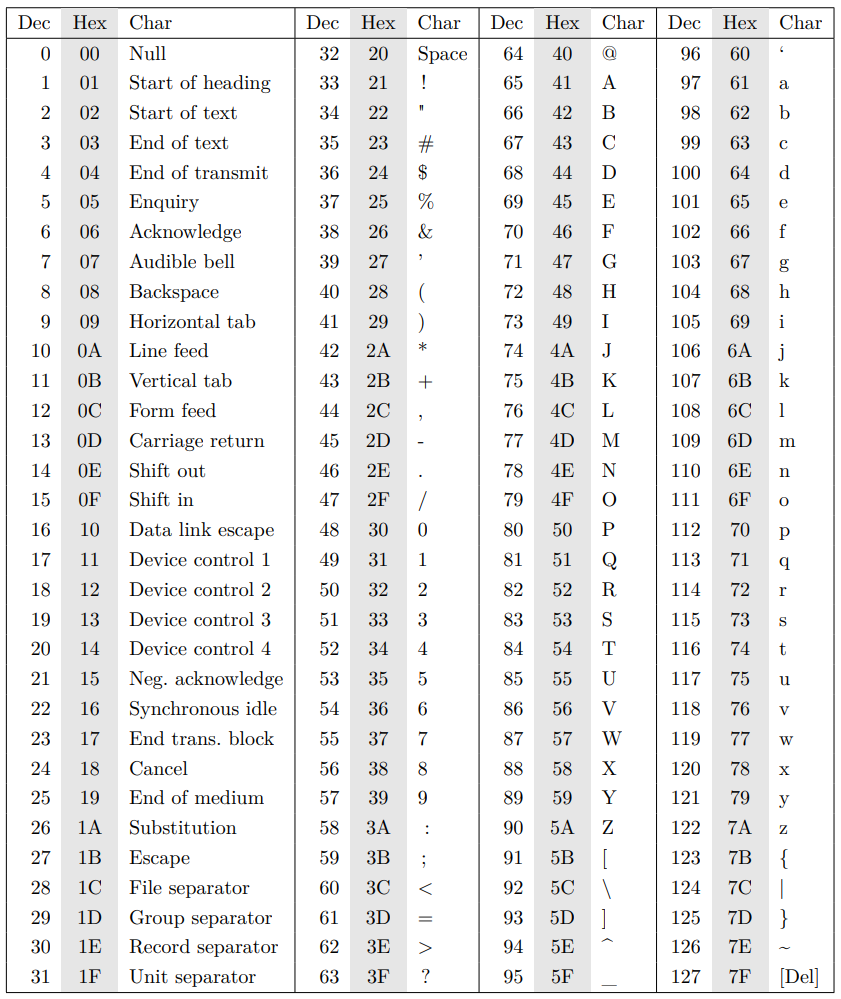
Le tableau ci-dessus semble désordonné, mais si on écrit le code hexadécimal, il y a une certaine logique:
Les codes 0 à 31 ne sont pas des caractère, on les appelle les caractères de contrôle (ex: retour à la ligne, bip sonore);
Le code 32 est l'espace;
Les codes 48 à 57 sont les chiffres;
Les codes 65 à 90 représentent les majuscules;
Les codes 97 à 122 représentent les minuscules.
Dans ce tableau, il n'y a aucun caractère accentué, car cette norme a été développée pour l'anglais. Ce code a été ensuite étendu à 8 bits pour pouvoir coder plus de caractères. Le problème est que le code ASCII étendu n'est pas identique dans tous les pays.
Exercice 9#
Convertir les chaînes de caractères en utilisant le code ASCII hexadécimal.
Exercice 10#
Convertir le texte suivant écrit en code ASCII hexadécimal.
Exercice 11#
Comment peut-on transformer un lettre majuscule en lettre minuscule et vice-versa en utilisant le code ASCII?
Solution
Le code de A majuscule en décimale est 65, pour a minuscule c'est 97. Il faut donc ajouter 32 (97-65) pour passer d'une lettre majuscule à l'équivalent en minuscule.
Unicode#
Une solution au problème des caractères spécifiques à chaque langue, comme les accents, est l'Unicode. L'Unicode est une table de correspondance capable de représenter plus d'un million de caractères, ce qui suffit largement pour inclure tous les caractères de toutes les langues, ainsi que des icônes et des emojis. Cependant, cette capacité nécessite d'utiliser jusqu'à 3 octets pour encoder un seul caractère.
Cela implique que le stockage d'un texte demanderait trois fois plus de mémoire qu'avec un encodage ASCII. Or, dans des langues comme le français, seuls quelques caractères supplémentaires (notamment les lettres accentuées) s'ajoutent à ceux déjà pris en charge par l'ASCII. Cela rend cette solution peu optimale.
UTF-8#
L'UTF-81Universal Character Set Transformation Format permet de représenter tous les caractères de l'Unicode tout en optimisant l'espace utilisé, grâce à une taille d'encodage variable selon le caractère. Les caractères les plus fréquents occupent ainsi le moins de place.
Il encode sur 8 bits (1 octet) toutes les valeurs du tableau ASCII.
Il encode sur 16 bits (2 octets) les caractères les plus courants des principales langues, comme les lettres accentuées.
Il encode sur 24 bits (3 octets) des caractères comme ceux utilisés en chinois, japonais et coréen.
Il encode sur 32 bits (4 octets) des éléments comme les emojis, les caractères mathématiques, et autres symboles.
Ainsi, la taille de l'encodage varie selon les caractères utilisés. Par exemple, en français, les lettres sans accents seront encodées sur 8 bits, tandis que les lettres accentuées nécessiteront 16 bits.
Encodage du mot Début avec les différents encodages:
ASCII
Le mot Début contient 5 caractères qui sont codés sur 7 bits. Nous auront donc besoin de \(5 \cdot 7 = 35\) bits. Comme le code ASCII n'a pas d'accent, le résultat sera Debut.Unicode
Le mot Début contient 5 caractères qui sont codés sur 3 octets (24 bits). Nous auront donc besoin de \(5 \cdot 24 = 120\) bits. Le résultat sera Début.UTF-8
Le mot Début contient 5 caractères. Les caractères sans accents sont codés sur 8 bits et ceux avec accents sur 16 bits. nous auront donc besoin de \(4 \cdot 8 + 1 \cdot 16 = 48\) bits. Le résultat sera Début.
Exemple d'encodage du mot Début avec l'UTF-8 en binaire:
L'Unicode du caractère é est U+00E9 qui en binaire donne 1110 1001
D |
é |
b |
u |
t |
|---|---|---|---|---|
01000100 |
11000011 10101001 |
01100010 |
01110101 |
01110100 |
Exercice 12#
Pourquoi n'utilise-t-on pas toujours l'Unicode étant donné que nous pouvons coder tous les caractères pour chaque langue?
Solution
Nous n'utilisons pas toujours l'Unicode, parce qu'il prend beaucoup de place de stockage : 3 octets par caractère. C'est le triple par rapport au code ASCII.
Exercice 13#
Quels sont les avantages et les inconvénients des différents encodages?
Solution
encodage |
avantages |
inconvénients |
|---|---|---|
ASCII |
Prend peu de place (7 bits par lettre) |
Ne permet pas d'encoder les caractères avec accents |
ASCII étendu |
Prend peu de place (8 bits par lettre) et permet d'encoder certains accents |
Pas standardisé donc différent suivant les pays |
Unicode |
Permet d'encoder tous les caractères possibles (accents, caractères chinois, ...) |
Prend beaucoup de place: 3 octets (24 bits) |
UTF-8 |
Universel et efficace: utilise 1 octet pour les caractères les plus fréquents. 2, 3 ou 4 octets seulement quand c'est nécessaire |